KafkaCustomer概念
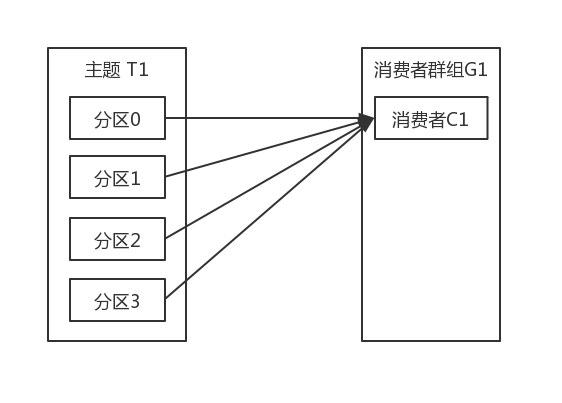
消费者和消费者群组 如果我们有一个应用程序需要从一个Kafka主题读取消息并验证这些消息,然后再把它们保存起来。应用程序需要创建一个消费者对象,订阅主题并开始接受消息,然后验证消息并保存结果。过一阵子,生产者往主题写入消息的速度超过了应用程序验证证据的速度,这个时候该怎么办?如果只使用单个消费者处理消息,应用程序会远跟不上消息生成的速度。显然,此时很有必要对消费者进行横向伸缩。就像多个生产者可以向同样的主题写入消息一样,我们也可以使用多个消费者从同一个主题读取消息,对消息进行分流。 Kafka消费者从属于消费者群组。一个群组里的消费者订阅的是同一个主题,每个消费者接手主题一部分分区的消息。假设主题T1有4个分区我们创建了消费者C1,它是群组G1里唯一的消费者,我们用它订阅主题T1。消费者C1将收到主题T1全部四个分区的消息,如下图所示:
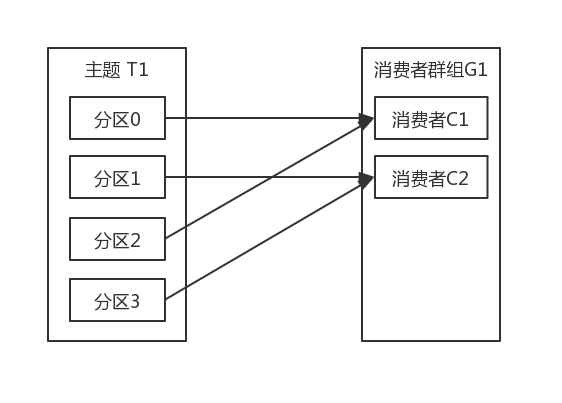
如果在群组G1里新增一个消费者C2,那么每个消费者将分别从两个分区接收消息。我们假设消费者C1接收分区0和分区2的消息,消费者C2接收分区1和分区3的消息,如下图所示:
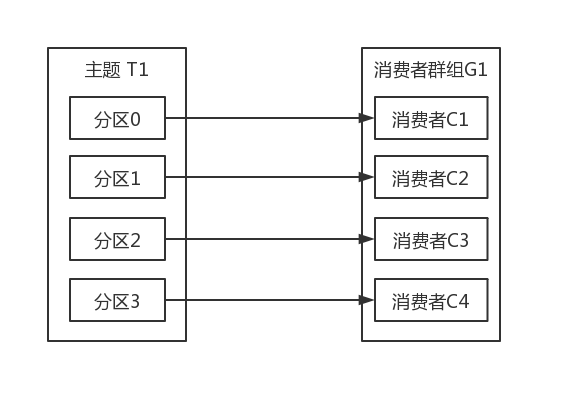
如果群组G1有四个消费者,那么每个消费者可以分配到一个分区,如下图所示:
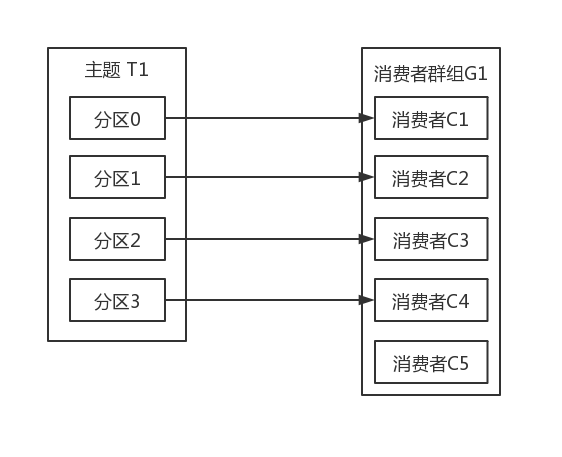
如果我们往群组里添加更多的消费者,超过了主题的分区数量,那么有一部分消费者就会被闲置,不会接收到任何消息,如下图所示:
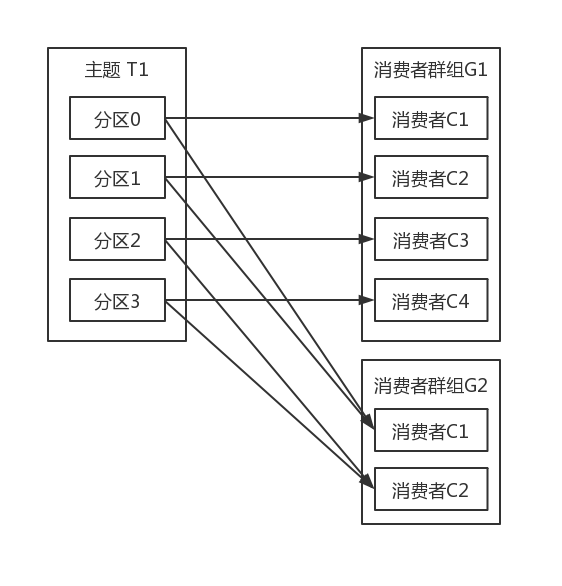
往群组里面增加消费者是横向伸缩消费能力的最主要方式。Kafka消费者经常会做一些高延迟的操作,比如把数据写入到数据库或者HDFS,或者使用数据进行比较耗时的计算。在这些情况下,单个消费者无法跟上数据生成的速度,所以可以增加更多的消费者,让它们分担负载,每个消费者只处理部分分区的消息,这就是横向伸缩的主要手段。我们有必要为主题创建大量的分区,在负载增长时可以加入更多的消费者。不过不要让消费者的数量超过分区的数量,多余的消费者只会被闲置。 除了通过增加消费者横向伸缩单个应用程序外,还经常出现多个应用程序从同一个主题读取数据的情况。实际上,kafka设计的主要目标之一,就是让Kafka主题里的数据能够满足企业各种应用场景的需求。在这些场景里,每个应用程秀可以获取到所有的消息,而不只是其中一部分。只要保证每个应用程序有自己的消费者群组,就可以让它们获取到主题所有的消息。不同于传统的消息系统,横向伸缩Kafka消费者和消费者群组并不会对性能造成负面影响。 在上面的例子里,如果新增一个只包含一个消费者的群组G2,那么这个消费者将从主题T1上接收所有的消息,与群组G1之间互不影响。群组G2可以增加更多的消费者,每个消费者可以像群组G1那样消费若干个分区,不管有没有其他群组的存在。如下图所示。 简而言之,为每个需要获取一个或者多个主题全部消息的应用程序创建一个消费者群组,然后往群组里添加消费者来伸缩读取能力和处理能力,群组里的每个消费者只处理一部分消息。
消费者群组和分区再平衡 从上文了解到,群组里的消费者共同读取主题的分区。一个新的消费者加入群组时,它读取的是原本由其他消费者读取的消息。当一个消费者被关闭发生崩溃时,它就离开了群组,原本由它读取的分区将由群组里的其他消费者来读取。在主题发生变化时,比如管理员添加了新的分区,会发生分区重分配。 分区的所有权从一个消费者转移到另外一个消费者,这样的行为被称为再均衡。再均衡非常重要,它为消费者群组带来了高可用和伸缩性(我们可以放心地添加或者移除消费者),不过在正常情况下,我们并不希望发生这样的行为。再均衡期间,消费者无法读取消息,造成整个群组一段时间的不可用。另外,当分区被重新分配给另外一个消费者时,消费者当前的读取状态会丢失,它有可能还需要去刷新缓存,在它重新恢复状态之前会拖慢应用程序。 消费者通过向被指派为群组协调器的broker(不同的群组可以有不同的协调器)发送心跳来维持它们和群组的从属关系以及它们对分区的所有权关系。只要消费者以正常的时间间隔发送心跳,就被认为是活跃的,说明它还在读取分区的消息。消费者会在轮询消息(为了获取消息)或者提交偏移量时发送心跳。如果消费者停止发送心跳的时间足够长,会话就会过期,群组协调器认为它已经死亡,就会触发一次再均衡。 如果一个消费者发生崩溃,并停止读取消息,群组协调器会等待几秒钟,确认它死亡了才会触发再均衡。在这几秒的时间里,死掉的消费者不会读取分区的消息。在清理消费者时,消费者会通知协调器它将要离开群组,协调器会立即触发一次再均衡,尽量降低处理停顿。 分配分区时怎么样的一个过程 当消费者要加入群组时,它会向群组协调器发送一个JoinGroup请求。第一个加入群组的消费者将成为“群主”。群主从协调器那里获得群组的成员列表(列表包含了所有最近发送过心跳的消费者,它们被认为是活跃的),并负责给每一个消费者分配分区。它使用一个实现了PartitionAssignor接口的类来决定哪些分区应该被分配给哪个消费者。 分配完毕之后,群组把分配情况列表发送给群组协调器,协调器再把这些信息发送给所有的消费者,每个消费者只能看到自己的分配信息,只有群主知道群组里所有消费者的分配信息。这个过程会在每次再均衡时重复发生。
创建Kafka消费者
在读取消息之前,需要创建一个KafkaConsumer对象。创建KafkaConsumer对象和创建KafkaProducer对象非常相似,把想要传给消费者的属性放在Properties对象里。在这里首先介绍三个必要的属性:bootstrap.server、key.deserializer和value.deserializer。 bootstrap.server 该属性指定broker的地址清单,地址的格式为host:port。清单里不需要包含所有broker地址,消费者会从给定的broker里查找到其他的broker信息。不过建议至少要提供两个broker信息,一旦其中一个宕机,消费者仍然能连上集群。 key.deserializer 消费者需要知道如何将这些字节数组转化为java对象。key.deserializer必须被设置为一个实现了org.apache.kafka.common.serializetion.Deserializer接口的类,消费者会使用这个类把接收到的字节数组反序列化成java对象 value.deserializer value.deserializer指定的类会将值反序列化。如果获取的字节数组是字符串序列化的值,可以使用与key.deserializer一样的反序列化器。如果键是整数类型而值是字符串,那么需要使用不同的反序列化器。 group.id 指定KafkaConsumer属于哪一个消费者群组。创建不属于任何一个群组的消费者也是可以的,只是这样做不太正常。 下面演示如何创建一个KafkaConsumer对象:
Properties props = new Properties();
props.put("bootstrap.server","broker1:9092,broker2:9092");
props.put("group.id","CountryCounter");
props.put("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String,String> consumer = new KafkaConsumer<String,String>(props);订阅主题
创建好消费者之后,下一步可以开始订阅主题了。subscribe()方法接受一个主题列表作为参数,使用起来很简单:
//这里为了简单,只创建了一个只包含单个元素的列表,主题名字叫做“customerCountries”
consumer.subscribe(Collections.singletonList("customerCountries"));也可以在调用subscribe()方法时传入一个正则表达式。正则表达式可以匹配多个主题,如果有人创建了新的主题,并且主题的名字与正则表达式匹配,那么会立即触发一次再均衡,消费者就可以读取新添加的主题。如果应用程序需要读取多个主题,并且可以处理不同类型的数据,那么这种订阅方式就很管用。在Kafka和其他系统之间复制数据时,使用正则表达式的方式订阅多个主题是很常见的做法。 要订阅所有与test相关的主题:
consumer.subscribe("test.*");轮询
消息轮询是消费者API的核心,通过一个简单的轮询像服务器请求数据。一旦消费者订阅了主题,轮询就会处理所有的细节,包括群组协调、分区再均衡、发送心跳和获取数据,开发者只需要使用一组简单的API来处理从分区返回的数据。消费者代码的主要部分如下所示:
try{
//这是一个无限循环。消费者实际上是一个长期运行的应用程序,他通过持续轮询像Kafka请求数据。
while(true){
ConsumerRecords<String,String> records = consumer.poll(100);
for(ConsumerRecord<String,String> record:records){
log.debug("topic = %s, Partition = %s, offset = %d, customer = %s, country = %s\n",
record.topic(),record.partition(),record.offset(),record.key(),record.value());
int updatedCount = 1;
if(custCountryMap.countainsValue(record.value())){
updatedCount = custCountryMap.get(record.value()) + 1;
}
custCountryMap.put(record.value(),updateCount);
JSONObject json = new JSONObject(custCountryMap);
System.out.println(json.toString(4));
}
}finally{
/**
* 关闭消费者。网络连接和socket也会随之关闭,并立即触发一次再均衡,
* 而不是等待群组协调器发现它不再发送心跳认定它死亡,因为这需要更长时间,导致整个群组在一段时间内无法读取消息。
*/
consumer.close();
}
}